이전에 패스트캠퍼스 리뷰 이벤트를 보고 리뷰를 남겨서 상금을 받은 적이 있다.
[완강][패스트캠퍼스] 대규모 언어모델 LLAMA를 활용한 프로젝트 구현과 Fine tuning - 후기
★ 100% 상태로 보기에는 그림도 글도 작아서 불편할 거에요. 250% 정도로 키워서 읽으시는 것을 추천합니다. 강의 링크 : https://fastcampus.co.kr/data_online_llama 대규모 언어모델 LLAMA를 활용한 프로젝트
hdnua.tistory.com
다시 생각해보면 이때 AI 일을 잡은 건 참 다행이라고 생각한다. 기초 수학이나 AI 기본 기술에 대한 지식을 익힌 건 물론이고, 고강도 훈련을 통해 공부하는 재미를 다시금 느낄 수 있었다. ChatGPT의 진가를 알게 되었고, LLaMa를 본격적으로 회사에 도입을 시도하면서 재미있는 여러 프로젝트를 해보게 됐다. Perl 2 Python Conversion with LLMs 같은 간단한 응용부터, RAG를 활용하여 Assembly Code를 자동 생성하는 챗봇을 구현하는 것까지. 내 학부 생활때가 생각나기도 하고, 내가 그래도 공부를 참 좋아했구나 싶더란다.
말 나온 김에 오블완을 하기 위해 하나 적어보자. 얼마 전에 AI 관련해서 회사에서 세미나를 했었다. 준비도 열심히 했고 발표도 잘했다. 발표에서 아쉬운 건 없는데, 왠지 계속 아는 척을 마구 하고 싶어서 그때 이 말까지 했다면 어땠을까 하는 망상이 줄곧 드는 것이다. 예를 들면 LLM의 역사 같은 것. LLM의 역사에 대한 건 위의 패스트캠퍼스 강의에서 나오는 건데. 내가 이해한 것은 이렇다.
태초에 Perceptron이 있었다. 인공지능에 대한 연구는 여러 갈래로 나뉘는데, 그 중 인간의 뇌의 요소인 뉴런을 본따려는 시도가 Perceptron 이었다. 예를 들어 분류 문제를 풀기 위해 인공 지능 중 Perceptron을 사용하는 상황으로 가정하자. AND 함수나 OR 함수의 경우는 Perceptron을 사용하면 해결할 수 있는 문제였다. 처음에 아무렇게나 선을 만든 다음, 주어진 입력들과 해당 직선 간의 오차를 구해서, 오차가 최소가 되는 선이 나올 때까지 회귀(regression)를 수행하면, 결국 모든 입력에 대해 올바르게 출력을 판정할 수 있는 선을 구할 수 있었다. 그러나 문제는 이 당시의 Perceptron은 단층(Single Layer)를 썼다는 것이고, 단층 Perceptron으로는 XOR 문제는 해결할 수 없었다는 것이다. 그래서 그 당시에서는 훨씬 성능이 잘 나오는 다른 분류 알고리즘으로 인공지능 연구가 이동해버렸고, 사실상 이 시점에서 Perceptron 연구가 상당히 늦춰지는 결과를 만들고 말았다. XOR 문제는 훨씬 나중에 다층 퍼셉트론(Multi-layer Perceptron)이 나오면서야 초평면을 통해 해결되었다고 알고 있다. 참고로 XOR 문제는 풀고 나면 이런 식으로 보인다. (라고 나는 이해하고 있다)

아래와 같이 둘 모두 평면에서 regression을 시작했지만 서로 다른 초평면으로 regression 되는 것도 참 흥미롭지 않은가?
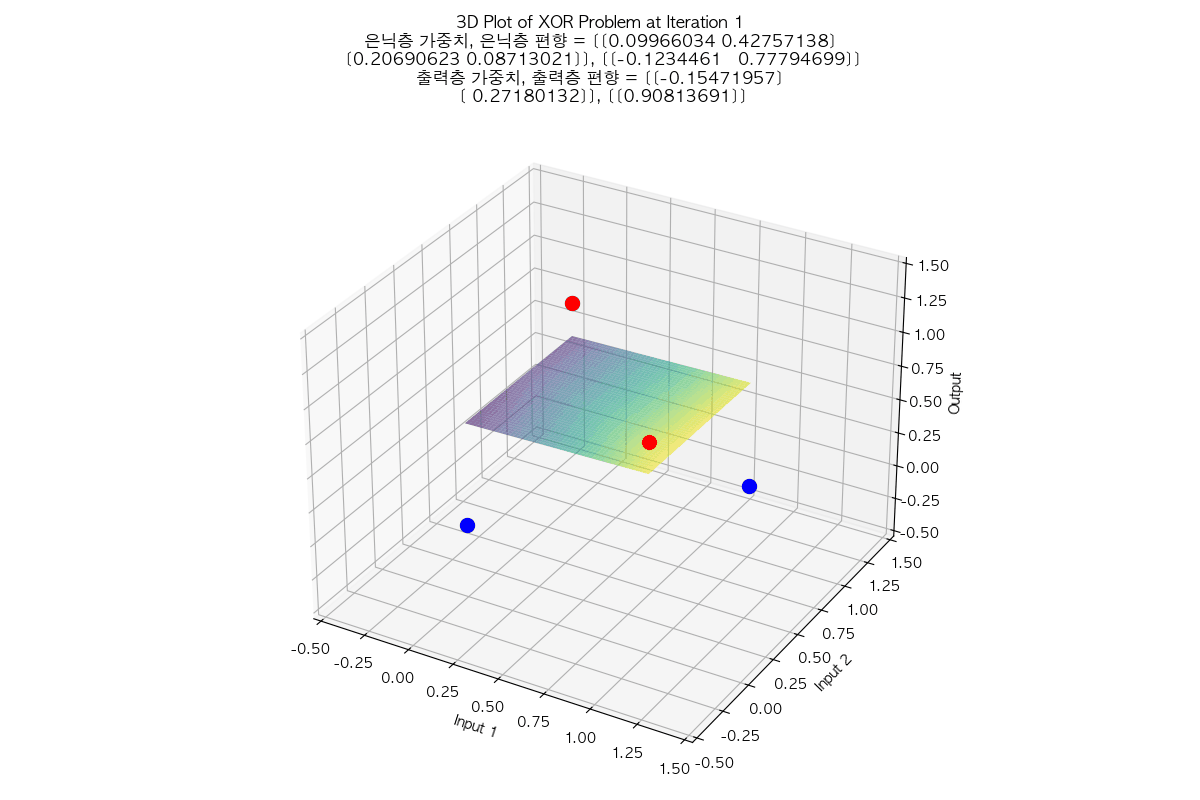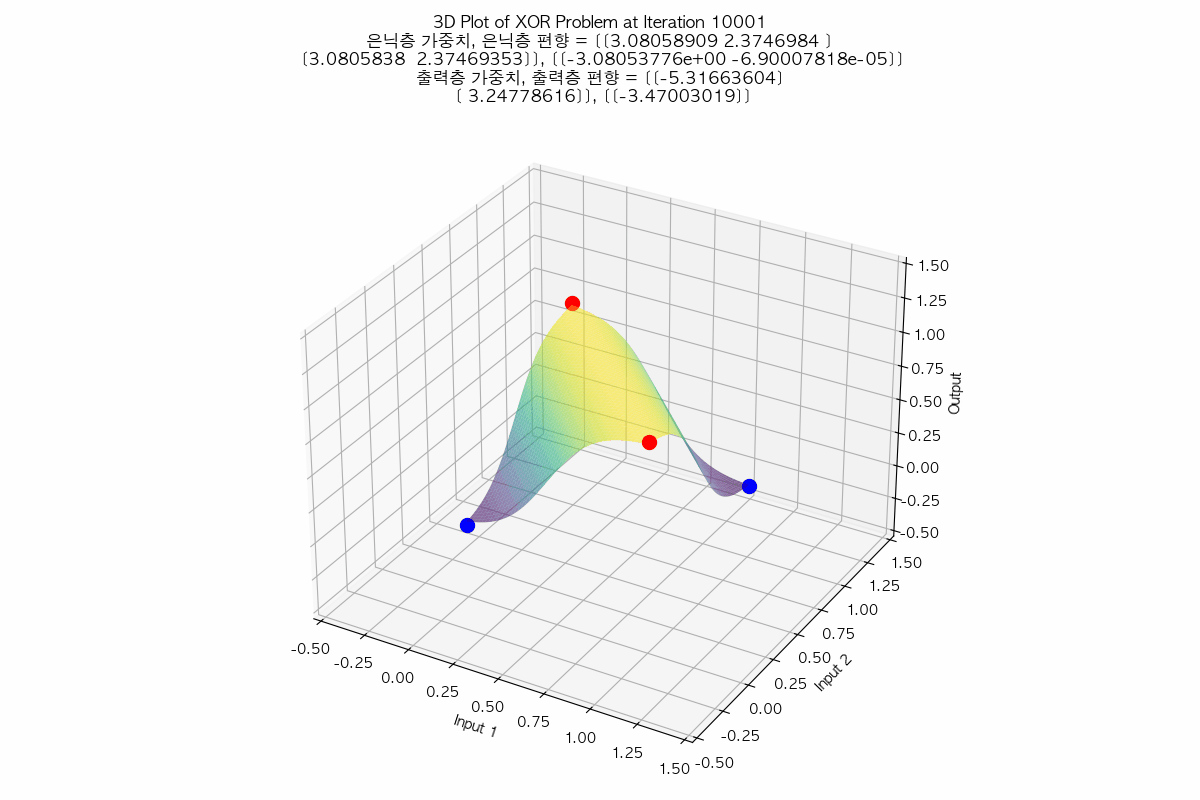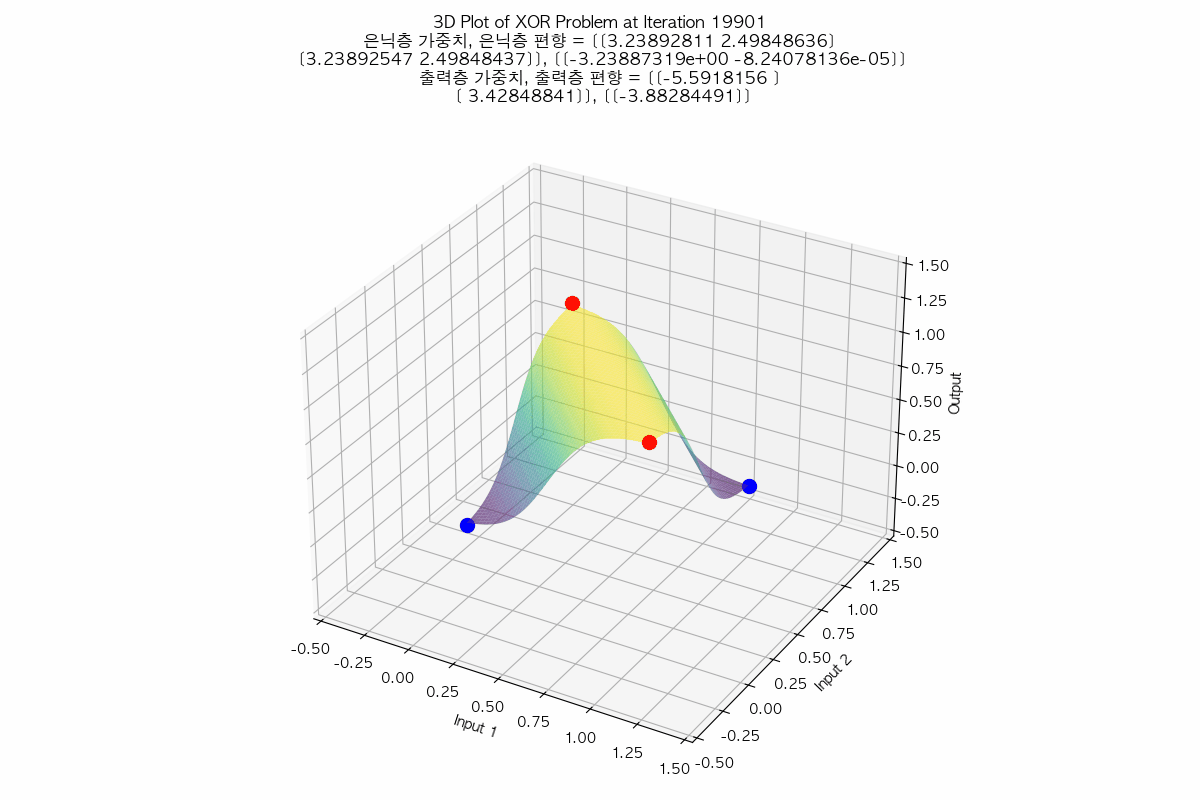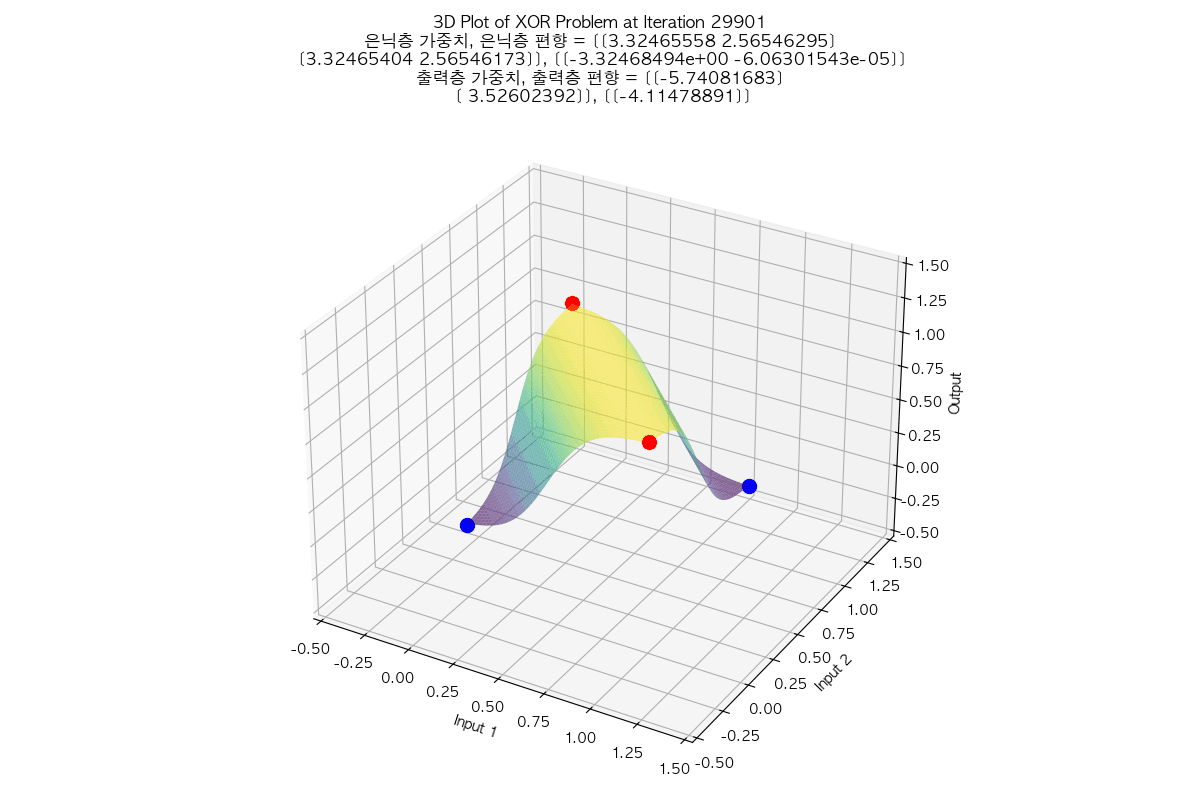 |
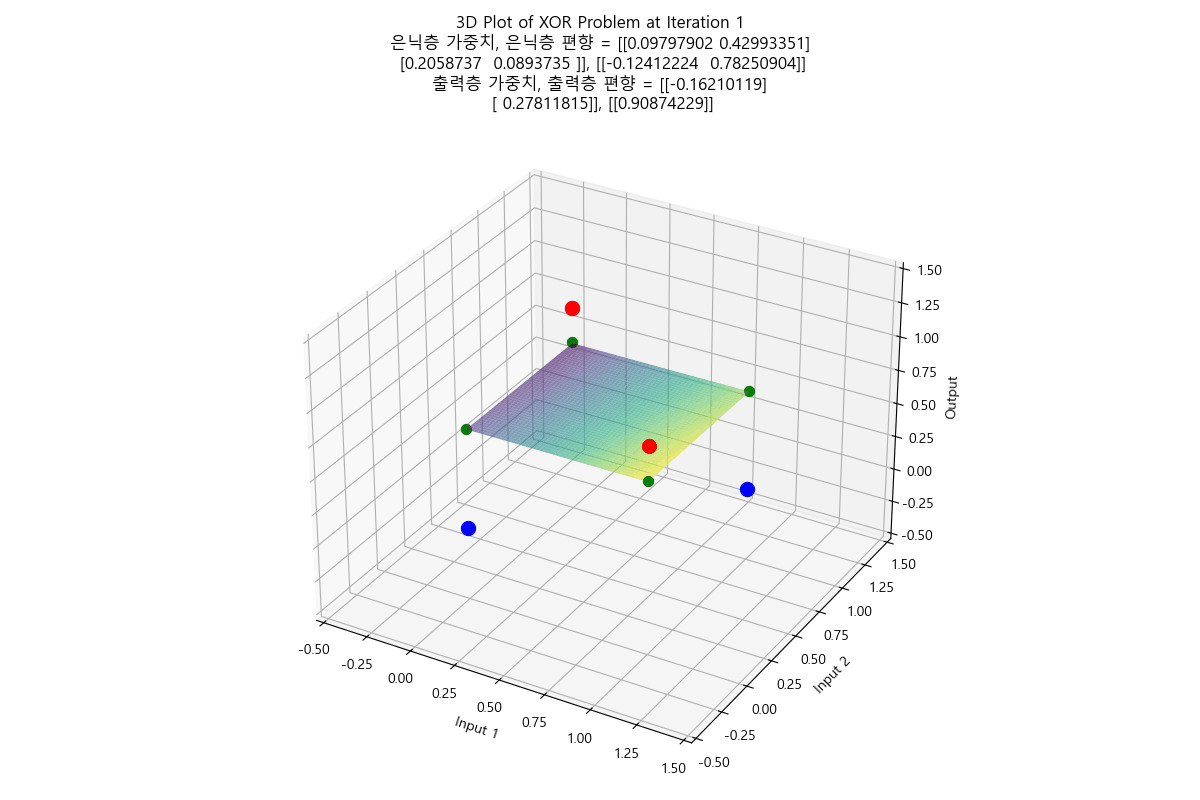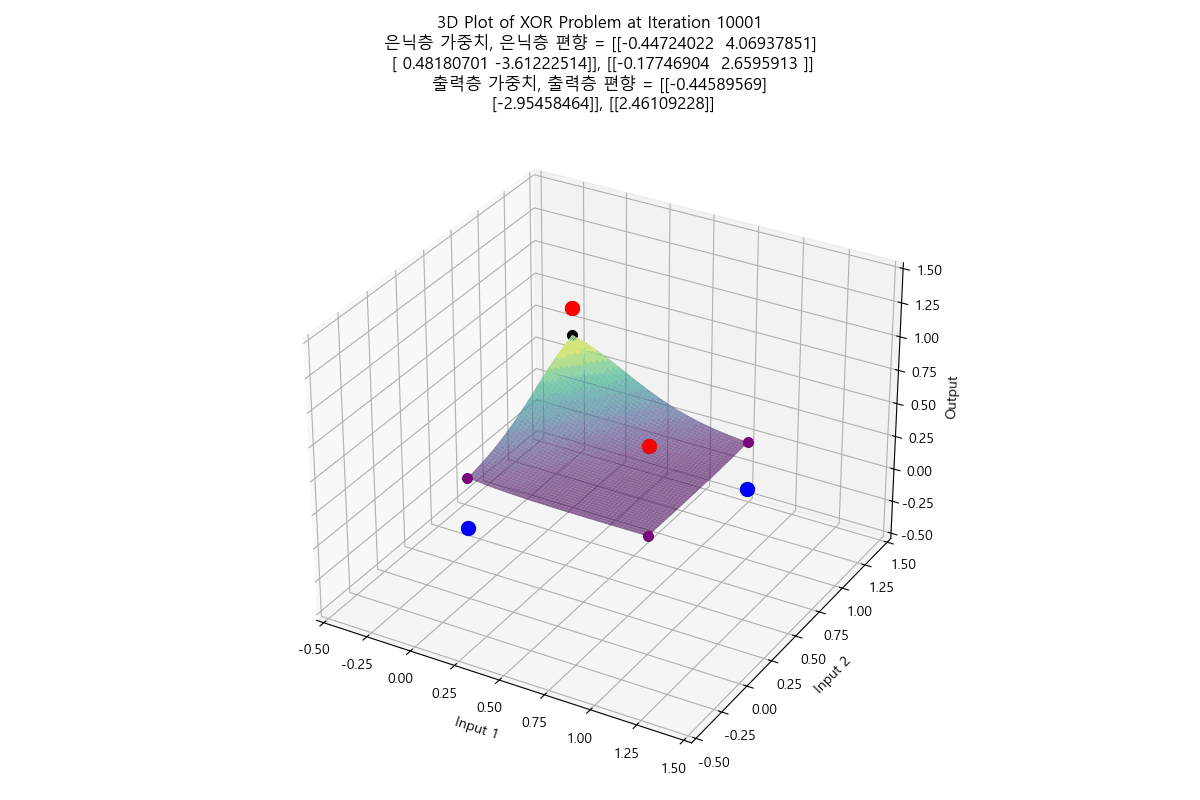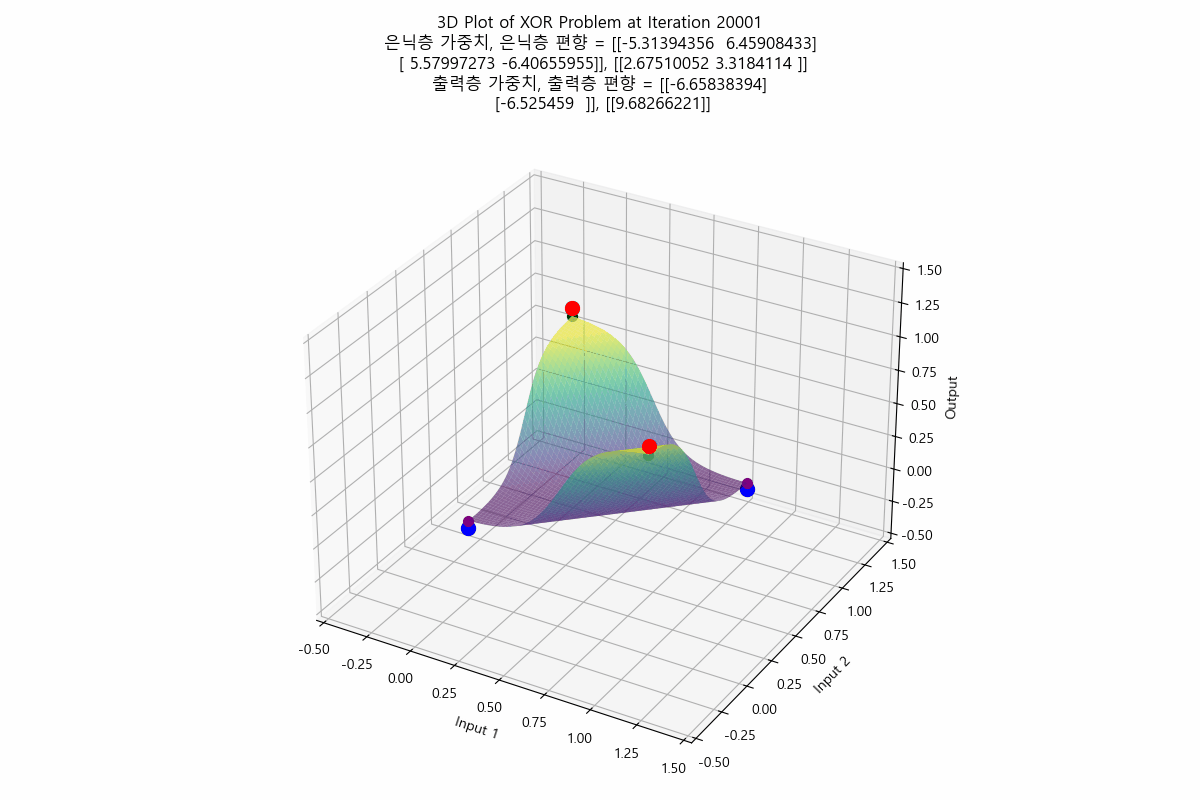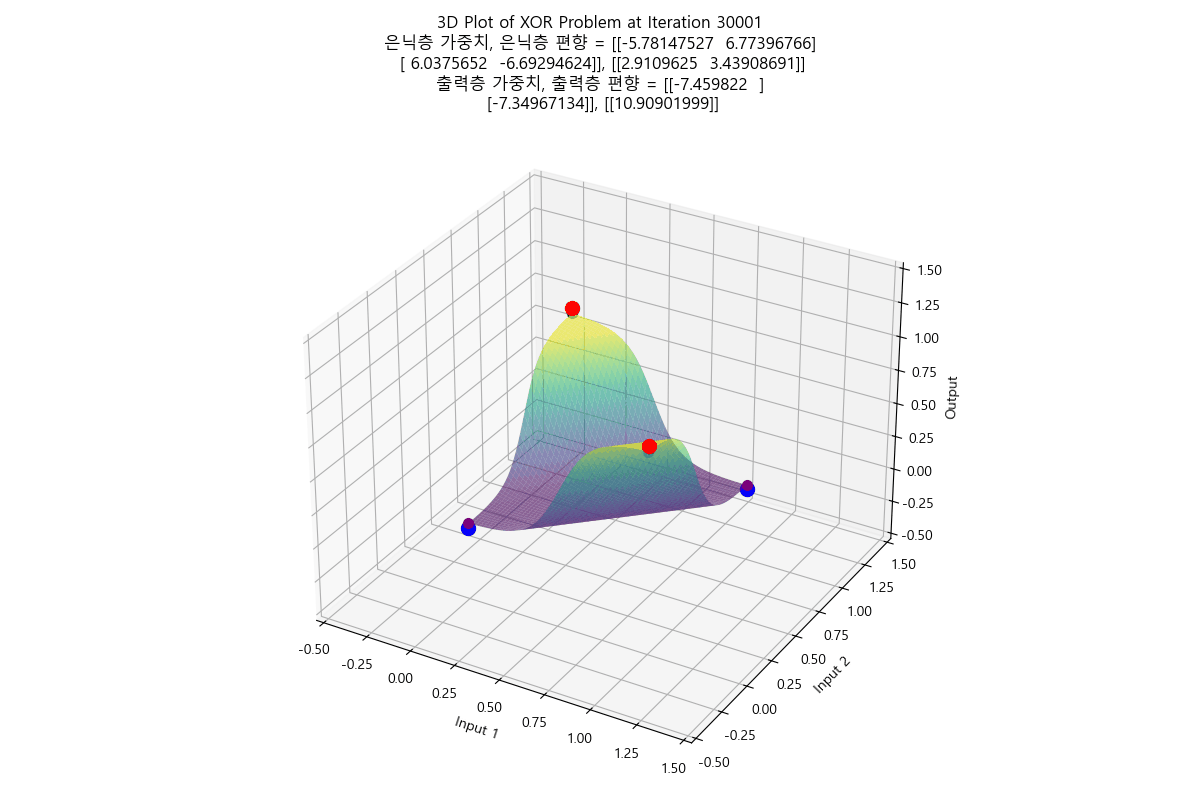 |
프로젝트가 궁금하다면 아래 내 git repo로.
https://github.com/HDNua/AIStudy/blob/master/231109-2224/1_perceptron.ipynb
AIStudy/231109-2224/1_perceptron.ipynb at master · HDNua/AIStudy
Contribute to HDNua/AIStudy development by creating an account on GitHub.
github.com
하튼 이런 연구가 쭉 진행되기도 하고 정체되기도 하다, 2012년 AlexNet이 Image 분류 대회에서 기존 대비 압도적인 성능을 내며 인공지능의 시대가 열리게 된 것이다. 이후 CNN(Convolutional Neural Network), RNN(Recurrent Neural Network) 등을 거치게 되었다. CNN의 경우는 Convolution 연산을 통해 기존 Neural Network가 모든 parameter를 update 하는 데 드는 비용을 Convolution Window 단위로 줄일 수 있게 되면서 극적인 성능 향상을 보여 Image 쪽에 활발히 연구되었던 것으로 알고 있고, RNN은 time series와 같이 어떤 것의 열(series)을 분석하는 데 Neural Network를 사용하기 위해 연구되었던 것으로 알고 있다. 예를 들면 텍스트 분석과 같은 과제.
NN 기준으로 텍스트 분석은 당연히 RNN을 위주로 시작이 되었고, 여기서 기억력을 보존시키기 위해 LSTM, GRU와 같은 기법이 연구되었다. LSTM 이후 Seq2Seq를 거치고 Bahdanau Attention이 나오게 되었으며, 이에 기반하여 Google에서 "Attention is all you need, Transformer"라는 논문을 발표하며 AI 연구는 다시 한 번 극적인 전환점을 맞게 된다. Transformer는 기존의 CNN, RNN을 대체할 만큼 강력하면서도 저비용이었고, 이로 인해 대부분의 연구가 Transformer로 이동하게 되는 결과를 낳는다.이 시점부터 그 유명한 GPT도 나오게 된다(Generative Pretrained Transformer). Text-to-Text-Transition-Transformer(T5)와 같은 기법도 나오고 BART, BERT와 같은 기법도 나오며 GPT는 GPT-2, GPT-3, InstructGPT를 거치며 진화했고, 현대에는 GPT-4o, 심지어는 PhD 급의 성능을 자랑한다는 GPT-o1 과 같이 괴물 성능의 인공지능까지 나오고 있다. Meta는 LLaMa를 필두로 초거대 언어모델을 오픈 소스로 풀어버리는 전략을 통해 ChatGPT의 대항마로서 자리매김해가는 것으로 보인다.
적고 보니 느끼는 것이지만 세미나 시간에 이런 걸 다 설명하면 8할은 졸고 있었을 것이므로 후회는 없다. ㅎㅎ 녹화가 가능했다면 두고두고 돌려보면서 아쉬운 점을 찾았을 거 같은 느낌. 마지막에 아래 책도 추천에 넣었는데, 팀원들이 하는 일이 다른 대기업도 고전하는 어려운 일이라고 말해주어 자부심을 느끼게 해주고 싶었다. 의도가 잘 전달됐던 것 같아 내심 기쁘게 생각하고 있다.
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=338192289
애플 엔비디아 쇼크웨이브
애플과 엔비디아가 반도체 시장에 뛰어들며 벌어진 격변의 현장과 새로운 반도체 질서의 형성을 다룬다. 이들 기업과 엮이며 새로운 역사를 쓰고 있는 TSMC, 인텔, ARM, 퀄컴, 삼성, 구글, 테슬라
www.aladin.co.kr
'해보기 > 2411 오블완' 카테고리의 다른 글
| 241112 오블완#6 과나 (0) | 2024.11.12 |
|---|---|
| 241111 오블완#5 카라멜 솔티드 아몬드 앤 프레첼 (0) | 2024.11.11 |
| 241110 오블완#4 어학 공부 (0) | 2024.11.10 |
| 241109 오블완#3 훈훈한 이야기 (0) | 2024.11.09 |
| 241107 오블완#1 시작 (0) | 2024.11.07 |



